What data should a vision-language model be trained on? To answer this question, many data curation efforts center on the quality of a dataset. However, most of these existing methods are (i) offline, i.e. they produce a static dataset from a set of predetermined filtering criteria, and (ii) concept-agnostic, i.e. they use model-based filters which induce additional data biases.
In this work, we go beyond such offline, concept-agnostic methods and advocate for more flexible, task-adaptive online concept-based curation. Our first contribution is DataConcept, a collection of 128M web-crawled image-text pairs annotated with fine-grained details about their concept composition. Building on DataConcept, we introduce Concept-Aware Batch Sampling (CABS), a simple yet effective batch-sampling framework that flexibly constructs batches on-the-fly based on specific target distributions.
We propose two variants: (i) Diversity Maximization (CABS-DM) to curate batches with broad coverage of available concepts, and (ii) Frequency Maximization (CABS-FM) to curate batches with high object multiplicity. Through extensive evaluations across 28 benchmarks, we demonstrate that CABS significantly benefits CLIP/SigLIP model classes and yields highly performant models. Overall, CABS represents a strong open-source alternative to proprietary online data curation algorithms, enabling practitioners to define custom concept distributions that optimize for specific downstream tasks.
We introduce DataConcept, a large-scale pretraining dataset with 128M image-text pairs fully annotated with grounded concept information. Each sample comes with: semantic concepts, bounding boxes, per-concept confidence scores, and concept-driven synthetic captions.
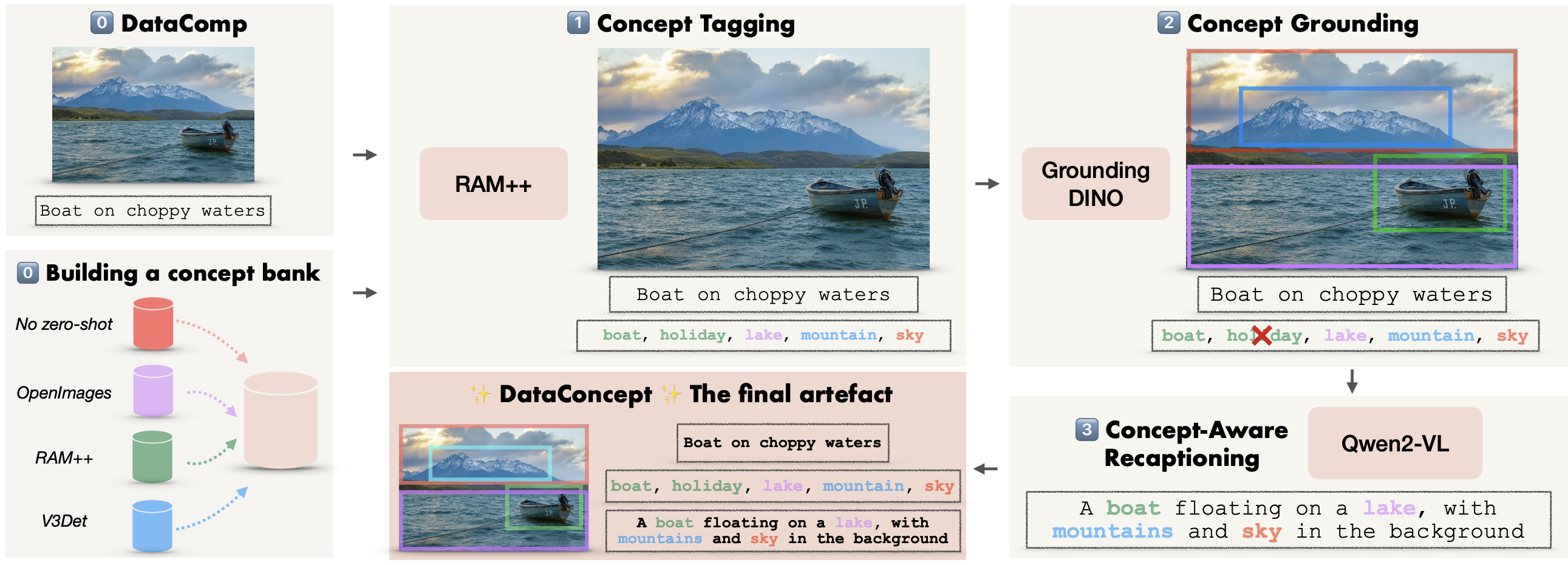
The complete DataConcept pipeline.
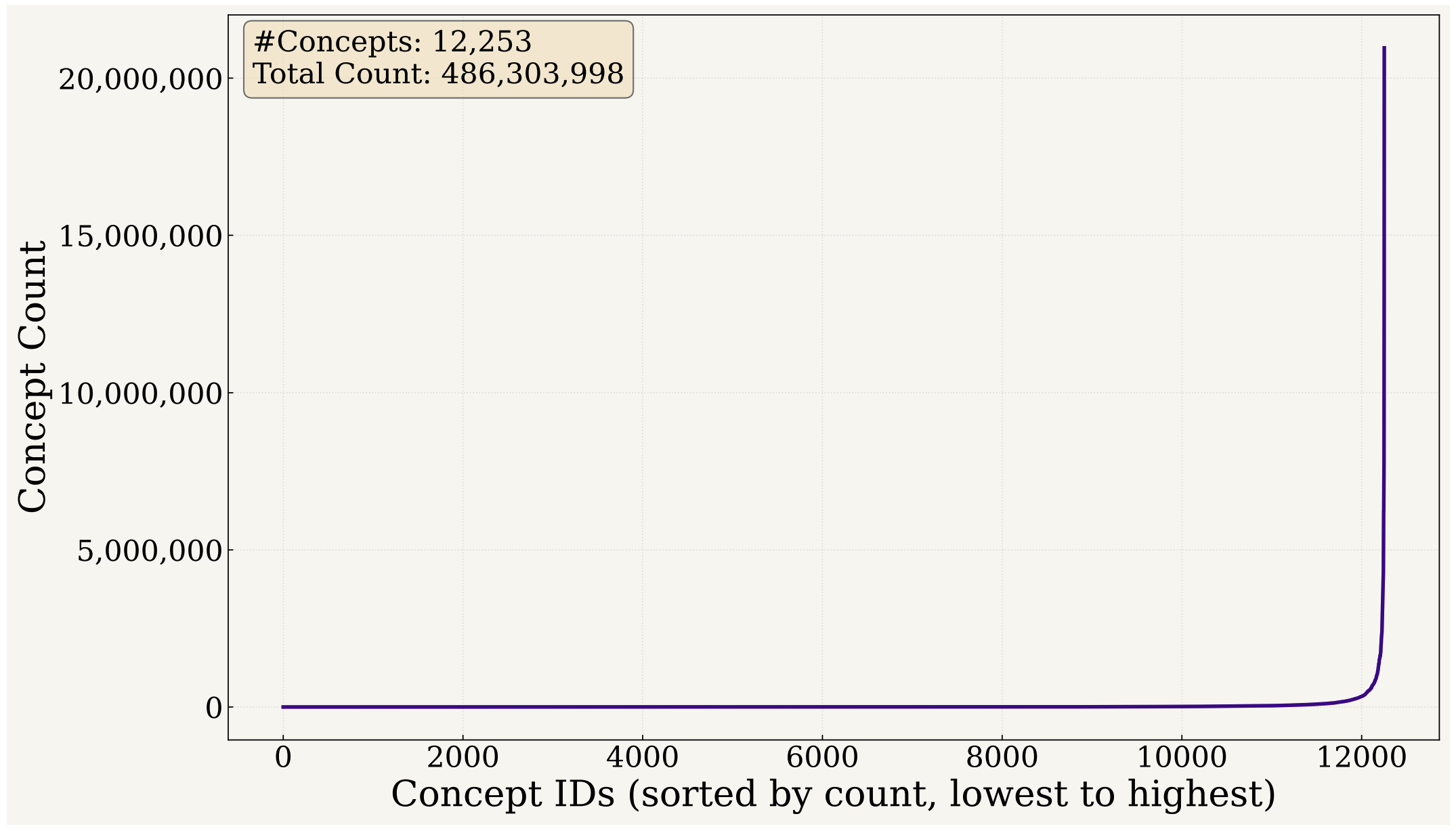
After tagging and grounding, we obtain a final concept vocabulary of 12,253 unique concepts across all 128M samples, exhibiting a long-tailed distribution.
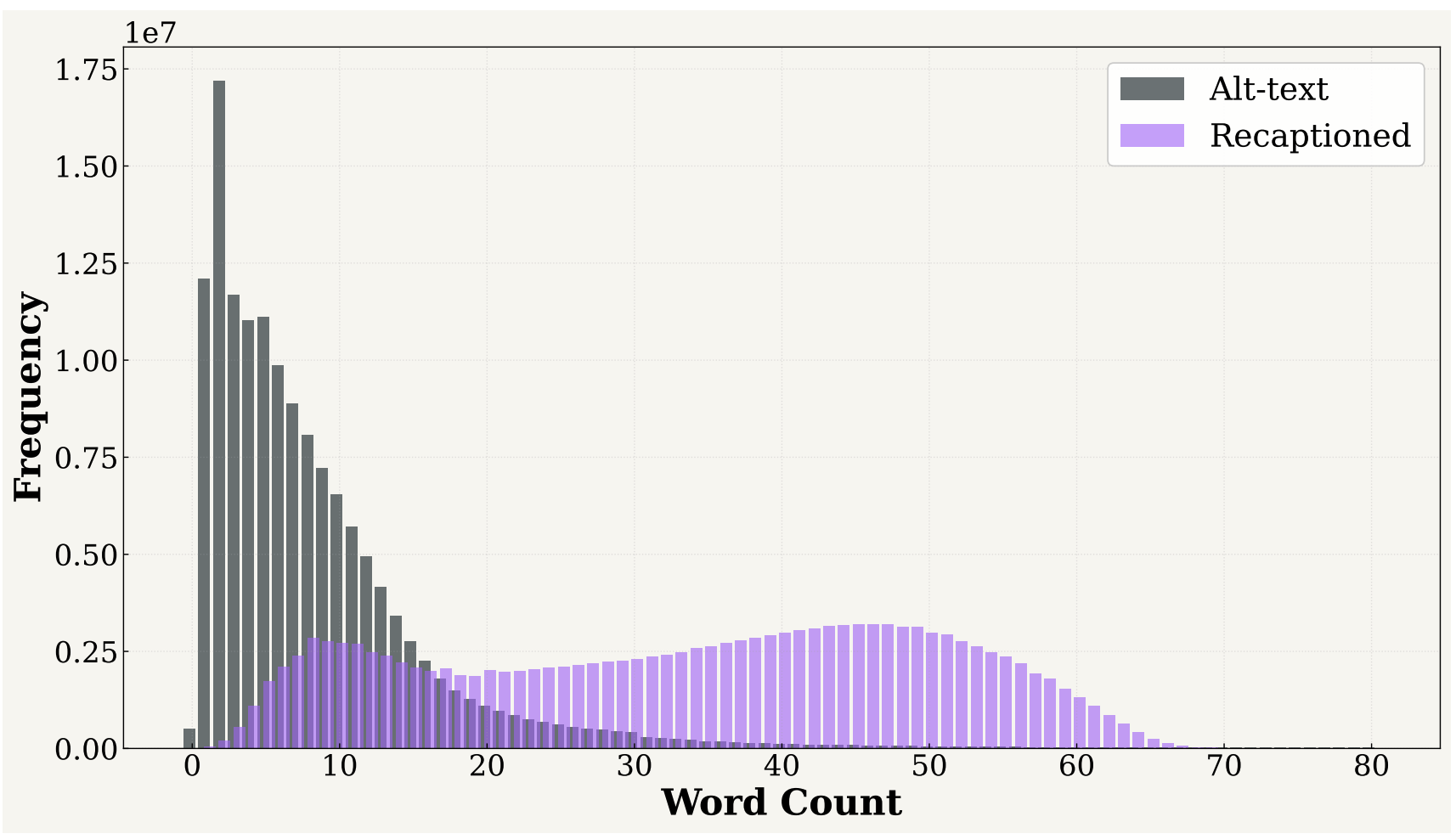
Our concept-aware recaptions are substantially richer than the original alt-texts: alt-text captions have a median word count of just 6, while recaptions have a median of 34 words with a much broader distribution.

A qualitative example of a DataConcept sample.
Our multi-stage pipeline consists of three steps:
DataConcept is publicly available on HuggingFace.
CABS is a parameterised sampling framework. Given a super-batch of size B drawn IID from the data pool, we define a target batch size b < B controlled by filter ratio f, such that b = (1 − f)B. For each sample with concept annotations, CABS computes a score using a concept-aware heuristic gain function and selects the top-scoring samples for training. By allowing the gain function to be flexible, practitioners can instantiate different batch sampling strategies and induce different concept distributions on-the-fly during training. We provide two such instantiations in this work.

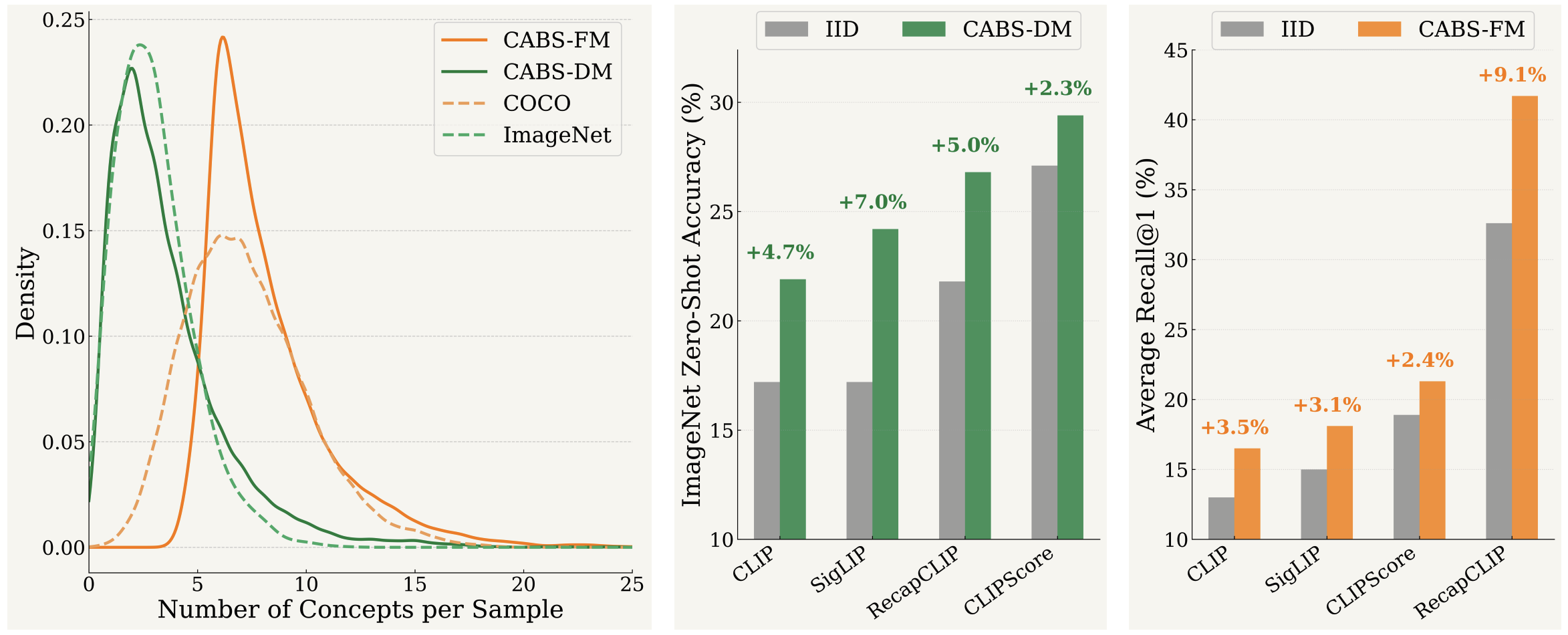
Designed for zero-shot classification. CABS-DM scores samples iteratively so that the filtered batch approximates a uniform concept distribution. It assigns higher scores to samples containing under-represented concepts and selects them greedily. An average CABS-DM sub-batch contains 1.5× more unique concepts than an IID-sampled batch, with a near-flat concept distribution.

CABS-DM induces a near-uniform concept frequency distribution, de-biasing the distributional skew of IID sampling. CABS-DM incorporates nearly double the unique concepts in the curated sub-batch.
Designed for image-text retrieval. CABS-FM uses a simple gain function based on concept count — it selects samples with the highest number of annotated concepts, yielding sub-batches enriched with complex, multi-object scenes that mirror the compositional nature of retrieval benchmarks.
CABS-DM consistently delivers substantial improvements over IID sampling across all settings. On ImageNet, CABS-DM yields absolute improvements of +5.0% for CLIP ViT-B/32 and +6.9% for SigLIP ViT-B/16. It also outperforms MetaCLIP-style offline curation and other online batch sampling methods (GRIT-VLP, MAFA).
| Method | Caption | Avg (Clf) | IN-Val | IN-shift | Obj | Scene | Let-It-Wag! |
|---|---|---|---|---|---|---|---|
| ViT-B/32 CLIP | |||||||
| IID | alt | 17.3 | 15.2 | 32.3 | 36.4 | 5.1 | 28.2 |
| CABS-DM | alt | 21.9 | 18.6 | 34.5 | 38.0 | 7.5 | 30.7 |
| IID | recap | 21.7 | 20.8 | 36.4 | 43.1 | 5.9 | 33.0 |
| CABS-DM | recap | 26.7 | 25.4 | 39.6 | 42.8 | 7.1 | 35.5 |
| ViT-B/16 SigLIP | |||||||
| IID | alt | 17.2 | 15.3 | 29.6 | 35.9 | 5.2 | 26.4 |
| CABS-DM | alt | 24.1 | 20.8 | 33.5 | 39.6 | 7.0 | 30.9 |
| IID | recap | 28.8 | 27.4 | 41.5 | 48.9 | 6.6 | 38.6 |
| CABS-DM | recap | 34.7 | 32.3 | 43.2 | 50.6 | 7.6 | 41.1 |
CABS-FM consistently outperforms IID sampling on retrieval benchmarks, yielding gains of up to +9.0% on average retrieval when training with recaptions. It also significantly outperforms existing online batch sampling methods.
| Method | Caption | COCO | Flickr | Avg (Ret) |
|---|---|---|---|---|
| ViT-B/32 CLIP | ||||
| IID | alt | 9.7 | 16.2 | 12.9 |
| CABS-FM | alt | 11.0 | 21.9 | 16.4 |
| IID | recap | 24.0 | 41.3 | 32.6 |
| CABS-FM | recap | 30.4 | 52.9 | 41.6 |
| ViT-B/16 SigLIP | ||||
| IID | alt | 11.1 | 18.9 | 15.0 |
| CABS-FM | alt | 12.3 | 23.9 | 18.1 |
| IID | recap | 37.1 | 57.0 | 47.0 |
| CABS-FM | recap | 39.7 | 63.5 | 51.6 |
We release CABS-trained model checkpoints on HuggingFace. All CABS variants are trained with a filter ratio of 0.8.
@article{ghosh2025concept,
title={Concept-Aware Batch Sampling Improves Language-Image Pretraining},
author={Ghosh, Adhiraj and Udandarao, Vishaal and Nguyen, Thao and Farina, Matteo and Cherti, Mehdi and Jitsev, Jenia and Oh, Sewoong and Ricci, Elisa and Schmidt, Ludwig and Bethge, Matthias},
journal={arXiv preprint arXiv:2511.20643},
year={2025}
}